Preface
写爬虫的时候遇到了这样一个警告
代码如下:
1 | from urllib.request import urlopen |
1 | UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently. |
根据提示信息,是因为没有指定解析器
以下是主要的解析器,以及它们的优缺点:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") |
1.Python的内置标准库 2.执行速度适中 3.文档容错能力强 |
Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
lxml HTML 解析器 |
BeautifulSoup(markup, "lxml") |
1.速度快 2.文档容错能力强 |
需要安装C语言库 |
lxml XML 解析器 |
BeautifulSoup(markup, "lxml") |
1.速度快 2.文档容错能力强 |
需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") |
1.最好的容错性 2.以浏览器的方式解析文档 3.生成HTML5格式的文档 |
1.速度慢 2.不依赖外部扩展 |
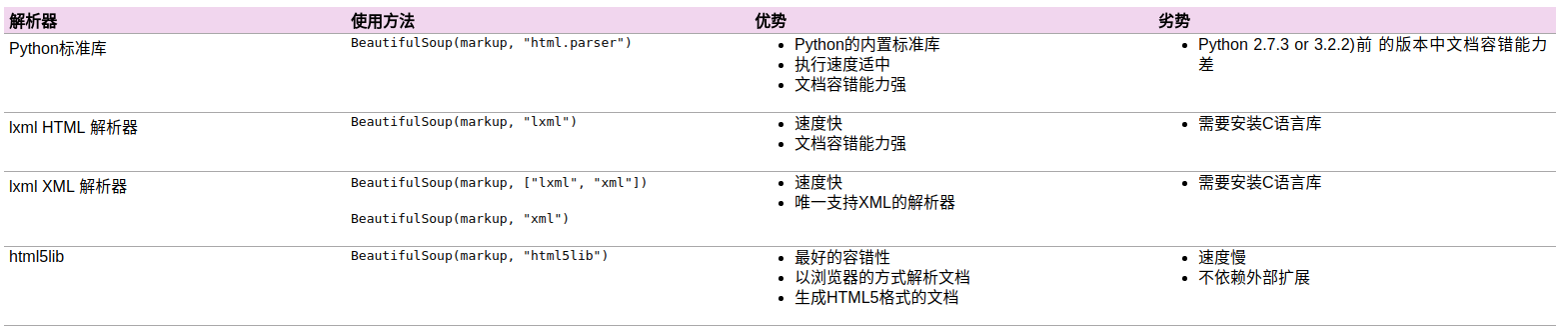
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
增加解析器即可:
1 | from urllib.request import urlopen |
参考
Beautiful Soup 4.2.0 文档
BeautifulSoup4 UserWarning
Markdown插入表格语法
表情符
用emoji表情提交代码指南
程序员提交代码的 emoji 指南——原来表情文字不能乱用
gitmoji的使用